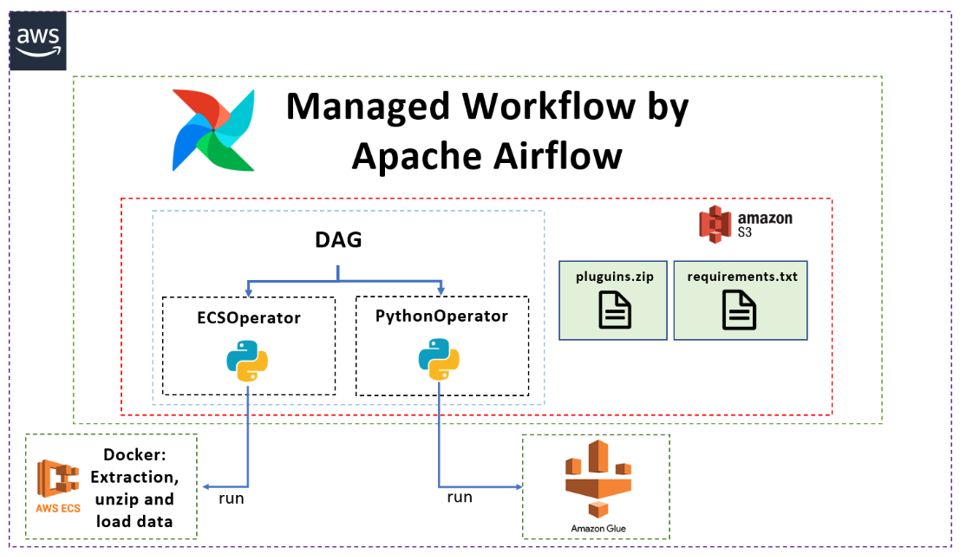
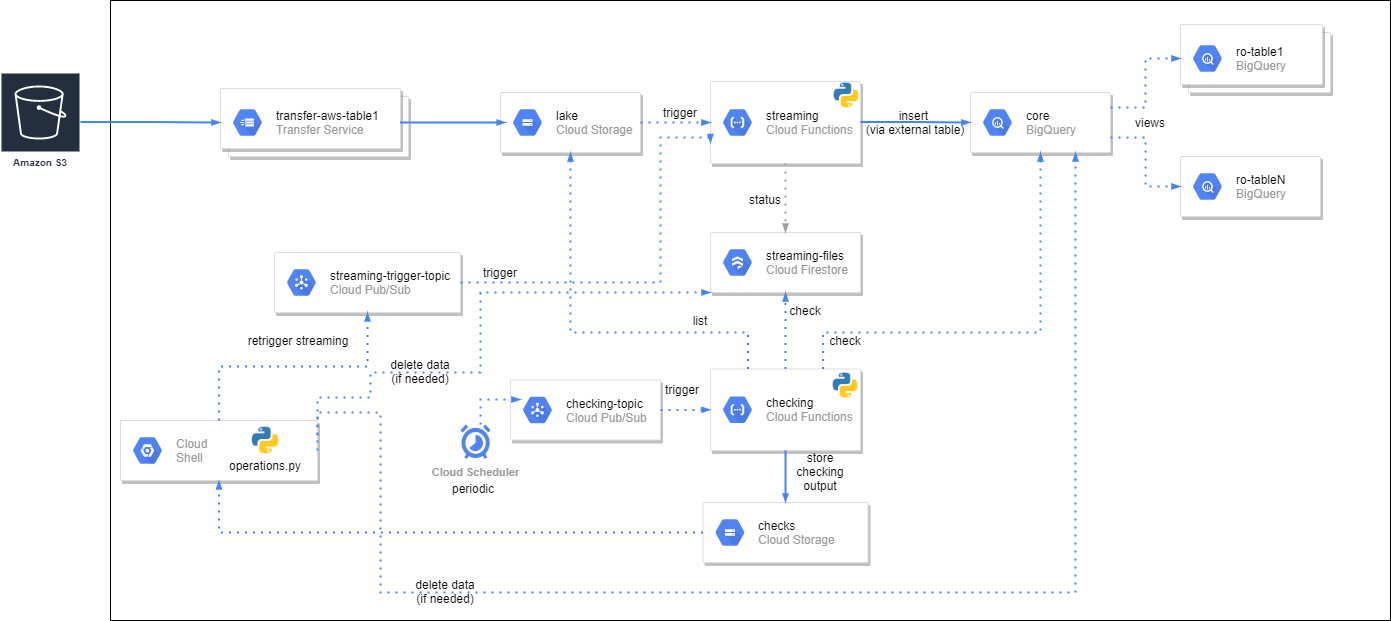
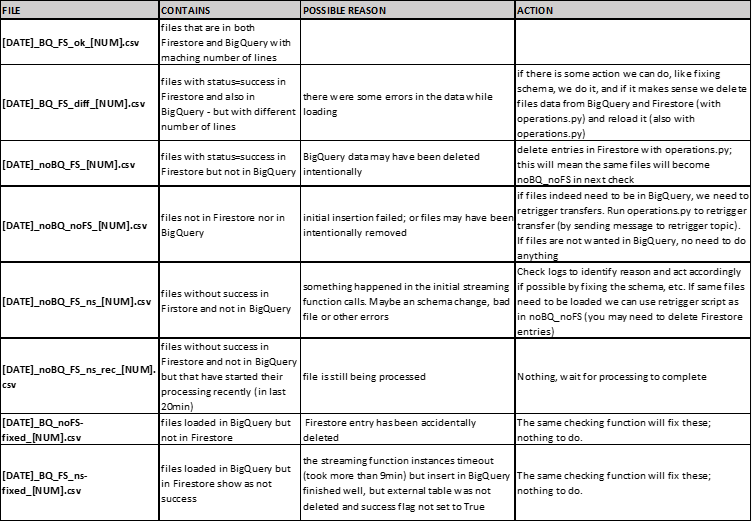
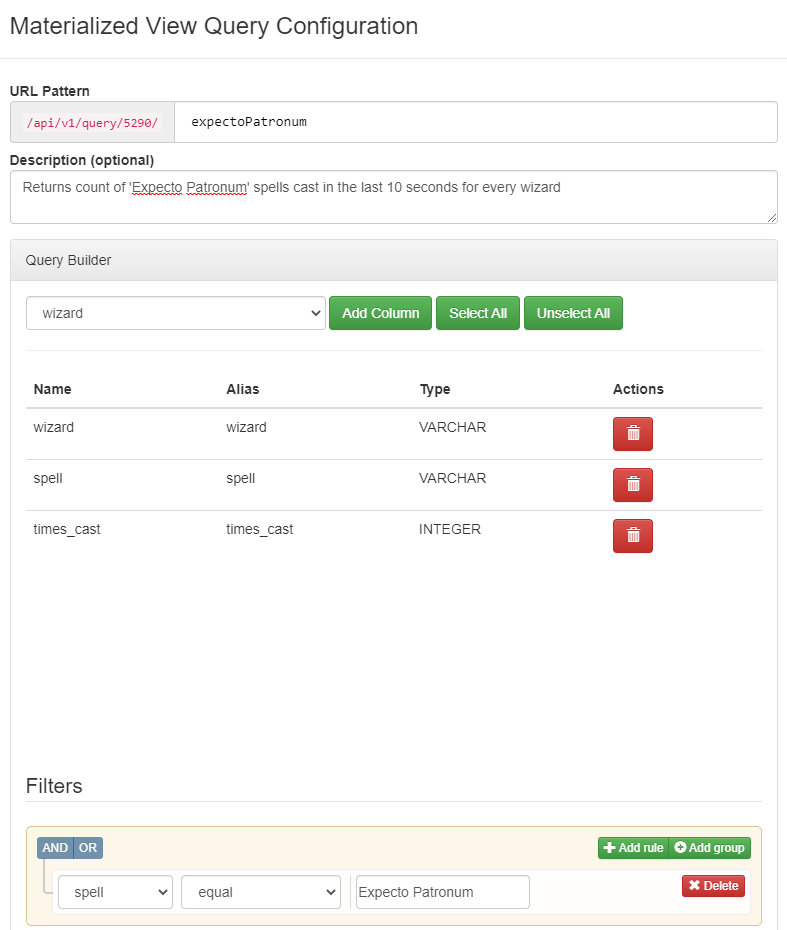
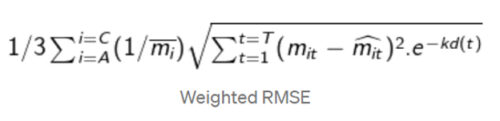What are Your Requirements?
The very first question these days when it comes to the infrastructure for an organisation’s data platform, regardless of the architecture/paradigm being implemented (Data Warehouse, Data Lake, Data Lakehouse, Data Mesh, etc.), is basically – on-prem or cloud? But before considering that, it’s important to get the requirements from the business.
What are we trying to achieve, what is this data platform going to be used for? High-level architecture or paradigm? What are the business problems that we are trying to solve? Are the business stakeholders educated on the possibilities of data? Do they understand what sort of things are possible and what sort of things are not possible? Or if they are possible, do they have an indication of how expensive that is in terms of time, money, and effort? Asking the right questions is crucial here.
Of course, it’s not possible to get all the requirements at once, but as I said before, if you can’t get the sample of these requirements, at least get the most important driving use cases.
On-Prem or Cloud?
Once we have the requirements as clear as possible, we can go back to the first question – the choice between cloud or on-prem. In general, the cloud offers many benefits – there is no large upfront investment, there is scalability, you don’t need to guess the required capacity of your platform, you just grow it with one click as you need.
Then there’s the availability of the clouds – in one click, you have a machine. And by availability, I also mean geographical availability. If you have a service running in the US and want to expand, in two clicks, you can have a service running in Australia or Asia.
We can also talk about the economies of scale. The cost per computer decreases the more computers you have, and of course one cannot compete in on-prem with the economies of scale that Amazon has, for instance.
There are also a lot of common showstoppers when organisations are trying to decide between cloud or on-prem, and I would say that there are two most common showstoppers. One is location. There are companies that say, “No, I cannot have my data off-prem or outside of our country.”
Of course, cloud vendors are aware of these concerns, and they are trying to address them now. Regarding the data location, the first thing they are trying to do is basically to bring their data centres to a larger number of physical locations, and in some cases, you can even have parts of AWS or Azure services on-prem.
The second major concern is about security – is the cloud secure? For this, I always respond with something that might sound a bit funny – can you imagine the amount of money and intelligence that giants like Amazon, Google, Oracle, and Microsoft invest into security issues?
Cloud platforms are secure – as long as you use them wisely, of course. If you have a cloud service, but you are using it unwisely and without proper governance and processes, then of course you can get into big problems, but if you know how to use cloud services and you use them well, they are as secure as an on-prem deployment.
Cloud Platforms
If, after consideration, you decide to choose a big data platform on the cloud, the next step is to choose a cloud provider. The four main contenders are AWS, Azure, GCP, and Oracle Cloud.
Traditionally, AWS is the market leader, though it seems like the competitors get a bit closer every year. When we look at the AWS offerings (and those of the rest), we have services to do almost all the things you can imagine of the data life cycle. For a few things, though, you may need help from external tools or services, which we will cover later on.
In AWS, the approach they take is kind of like Lego pieces. You can think of the different AWS services as Lego pieces; and to build a platform, you may need to put a lot of these pieces together. This requires a certain level of IT strength to implement.
On the other hand, Azure, which is, I would say, the most direct competitor of AWS, the services they have to build a data platform are easier to use, and normally you don’t require so many “Lego pieces”.
In an Amazon data platform, you may easily need 15 different types of services to do something. In Azure, maybe you need three or four different services. From a logical point of view, it’s usually easier to understand the logical structure of an Azure platform. Of course, that kills a bit of the flexibility.
So there is a trade-off – the more granular your Lego piece is, the more flexible you are. I’m not saying AWS is better or worse than Azure. It depends on your team, and on what you want to achieve.
The other main providers that we have in the picture, at least at ClearPeaks, are Oracle Cloud and GCP. GCP is pushing very hard and doing things very well. We have actually implemented GCP projects lately for some customers because of finding something in GCP that is just better and easier than the rest. So they are still not at the market leadership level of Azure, or AWS, but they are getting there.
Then we have the Oracle Cloud which is a great fit for Oracle customers that like Oracle’s robustness and Oracle products and services. Their offering is everyday more mature than the previous day. And likewise, we have recommended Oracle cloud to some customers, because we found that it made sense for the requirements of that situation.
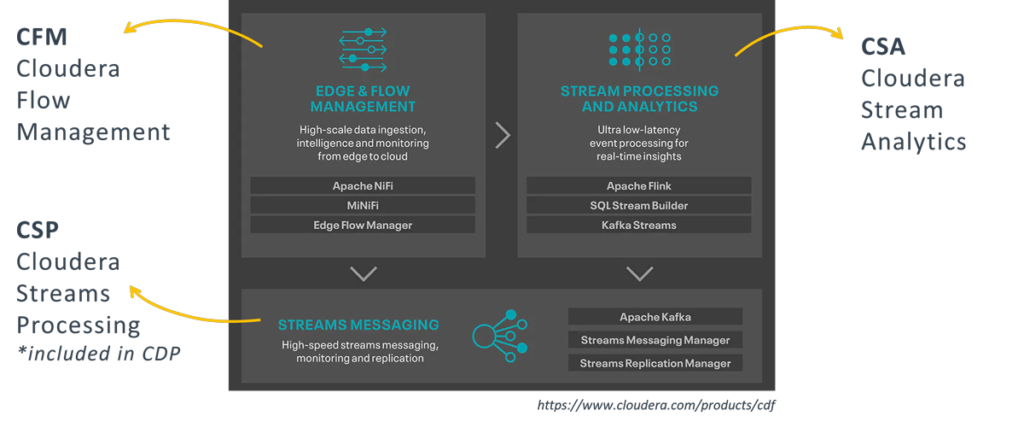
When we talk about data and data platforms, there are a few other companies on our radar; which are Cloudera, Snowflake, Databricks, and Dremio. Those companies also have offerings to run on cloud.
We use Cloudera a lot with our customers. On the on-prem, as I will say later, they are unrivalled. And when it comes to the cloud, especially when you want to deal with multi clouds, with hybrid things like cloud and on-prem, or when your required workloads are very varied, then Cloudera becomes the best option.
Snowflake is a cloud data warehouse. If you need a data warehouse in the cloud, Snowflake is probably one of the best options out there. They are trying to win market share by trying to expand the scope of the services they offer, aiming at a data lakehouse and including streaming, machine learning, and more.
Databricks was started by the same people that created Spark, so it has the best Spark you can find. And like Snowflake, Databricks is also trying to evolve the scope of what it offers, from having just the best Spark on cloud to creating a data lakehouse with Delta Lake technologies and making a lot of investment on offerings related to machine learning and artificial intelligence.
Dremio is also positioned as a lakehouse platform and offers quite a few different approaches compared to other technologies. It has recently released a pure SaaS (Software as a Service) offering so it is also starting to be a mature alternative.
So between AWS, Azure, GCP, Oracle Cloud, Cloudera, Snowflake, Databricks and Dremio, I would say that more than 90% of your needs are covered. There still maybe some cases that you may need support.
When you think about the internal part of the data platform, you are more than covered with all these providers, but when you think about the peripheral areas of the data platform like data ingestion, orchestration, CI/CD, automation, governance, federation and virtualisation, or visualisation, you may need something more.
For example, AWS, Azure, and other providers are fine with ingesting data between their services. But if you want to ingest data from outside, they are not as good, and you may need a tool for ingestion specifically. Then you have some nice platforms out there like Informatica or Talend, which not only deal with ingestion, but they also allow you to do orchestration, governance, and other things in one single platform.
Then onto visualisation – again, most of the providers I’ve mentioned have visualisation services, but they are maybe lacking the robustness of other technologies that have been serving as visualisation layers for many years, such as Tableau. This is why we often see Tableau in tandem with these technologies.
On-Prem Deployments
If an organisation wants on-prem, that may not only be because of security concerns, or like I said before, the data location. There is a third reason for staying on-prem, and I have recommended it myself sometimes. If you know exactly what you need and how big you are, and you have the team that knows how to do it, on-prem is the best option. In this case, it’s going to be cheaper to be on-prem in the long-term.
We’ve done that study with one of our customers. They wanted a platform, and they knew perfectly what they wanted. So we could size it accurately and make a good comparison. What we found out was that for this particular customer, cloud was cheaper in the beginning of course, because for on-prem you had to buy the equipment.
But then we also tried to estimate the demand, effort, and all the other variables. Through this analysis and estimation, we found that if the platform was going to be 100% utilised, over five years, the on-prem was going to be cheaper than the cloud. For the first four years, cloud was going to be cheaper, but after five years, the on-prem started to be the cheaper option.
Then at this point, you can wonder – in five years, is the platform really going to be doing what I want to do at that point? Probably not. But still, my point is that there are still some situations in which the requirements, forgetting about data location and security, may still make it a sensible choice to stay on-prem.
After making the decision to go for an on-prem deployment, we need to think about what tool stacks are available. Our preferred contenders are the ones we have mentioned in this article – but there are many more technologies out there!
There is also an increase of the open-source movement, so you can see data platforms with stuff like PostgreSQL, MySQL, Superset, a lot of Python and R for the machine learning use cases, Airflow for orchestration, etc. Some of these traditional open-source tools like Airflow, for example, are now becoming integrated into the clouds. Amazon just released a managed Airflow, and Google has already had it for a while. So we’re seeing some interesting movements now in this space.
Private Cloud
There are two flavours in on-prem – bare-metal, in which you install what you need directly on the machine; or you have a virtualisation layer that sits on top of bare-metal, which is referred to as a private cloud.
In a private cloud, you basically have a bunch of virtual machines on which you install whatever you want. This virtualisation layer has a penalty in terms of efficiency. You always have better performance when you have whatever you want installed directly on your bare-metal machine, versus having a virtualisation layer. Having a virtualisation layer adds some overhead that makes things a bit slower, but it gives a lot of flexibility.
It’s very common to have private cloud deployments in on-prem, it gives you something similar to the IaaS (Infrastructure as a Service) that you get on the cloud. While concepts like PaaS (Platform as a Service) and SaaS have been limited to the cloud, this is changing a bit lately in the data world, thanks to Kubernetes, Docker, and the like. In Cloudera, for example, they have recently released something called the analytics experiences which allow you to have the kind of ephemeral experience you would get on a cloud, with on-prem. It is going to be more and more common to have these ephemeral experiences also with on-prem.
Consider the Cost
When we think about on-prem, it’s a given that it is more expensive than cloud because you need to have the infrastructure and the people to deploy and maintain your platform. But sometimes in cloud, there’s something that is a bit tricky to navigate. When one puts a data platform in the cloud, there is a change of mindset that one needs to have, which is basically, you always need to look at your pocket.
As Amazon will tell you, you pay for what you use. That can be as granular as paying per query. So if that query that you run is not efficient, you may be incurring a high cost that you don’t expect. It can run into thousands of Euros for a single accidental bad query. This means that whenever you’re developing something on the cloud, you always need to have this concern, which I would say is a bit less worrying in on-prem.
If you do a bad query on on-prem it’s not as catastrophic as it can be on the cloud. Of course, clouds have measures to help you prevent these mishaps. But they are measures that you need to always have in your mind, basically setting guard rails that prevent extra costs.
Conclusion
Whichever vendor and architecture you choose, the success or failure depends on how well it fulfils the business requirements. It’s important to always have a business-driven initiative in this case.
And of course, we are happy to help you get this clarity. We have these conversations regularly and would love to talk to you. Simply contact us!

The post How to Choose the Right Big Data Platform for Your Business appeared first on ClearPeaks.