In our previous article we showed how to set up a streaming pipeline to write records to Hive in real-time, using Kafka and NiFi. This time, we will go one step further and show how to adapt that pipeline to a Kerberized environment.
If you are running a cluster in an enterprise, or if you are managing it for a client of yours, chances are that it is secured and integrated with Kerberos. Kerberized clusters require keytabs to be created and distributed in order for service accounts and user accounts to run jobs.
NiFi’s processors, of course, allow for Kerberos credentials to be specified; but the details of the process are not always clear to everybody. Similarly, Kafka producers require Kerberos information to be passed via certain configuration files. Let’s have a look at how to set these properties correctly.
Notes:
- To run this example, you need a Kerberized CDH cluster with NiFi.
- Our cluster has 1 Zookeper node and 1 Kafka broker node. These are not optimal settings for production environments, and are only valid for development/testing
1. Kafka Producer
In our previous article, we were able to run Kafka producers without worrying about credentials. Once the cluster is Kerberized, however, Kafka requires the following two settings:
- The KAFKA_OPTS variable to point to a valid JAAS configuration file.
- The producer.config parameter to point to the right client properties file.
1.1. Keytab
First of all, we need to create a keytab for the credential we want to run our producer as, since Kafka will not prompt for a password to be manually inserted.
To create a keytab, we run the ktutil utility.
# ktutil ktutil: addent -password -p your_user@YOUR.DOMAIN -k 1 -e arcfour-hmac Password for your_user@YOUR.DOMAIN: ktutil: wkt /home/your_user/your_user.keytab ktutil: exit |
Note that the -e option specifies the encryption type. This might vary depending on your cluster settings.
You can test your keytab in the following way:
# kinit -kt your_user.keytab your_user@YOUR.DOMAIN # klist Ticket cache: FILE:/tmp/krb5cc_0 Default principal: your_user@YOUR.DOMAIN Valid starting Expires Service principal 05/02/2021 11:55:15 05/02/2021 21:55:15 krbtgt/YOUR.DOMAIN@YOUR.DOMAIN renew until 05/09/2021 11:55:15 |
1.2. JAAS Configuration
The jaas.conf file should contain information about your Kerberos credentials. It should have the following content:
KafkaClient {
com.sun.security.auth.module.Krb5LoginModule required
useKeyTab=true
keyTab="/home/your_user/your_user.keytab"
principal="your_user@YOUR.DOMAIN";
};
|
The keyTab and principal values should, of course, match the ones defined during the creation of the keytab.
1.3. Client Properties
The client.properties file should contain information about the security protocol and the name of the Kafka service credential in Kerberos. It should have the following content:
security.protocol=SASL_PLAINTEXT sasl.kerberos.service.name=kafka |
The service name should be different if you named the Kafka service account differently.
1.4. Starting the Producer
At this point, we have everything we need to start our producer. Assuming we have a kafka_example folder in our home directory, we run the following commands in order to replicate the same stream from our previous article:
# export KAFKA_OPTS="-Djava.security.auth.login.config=/home/your_user/kafka_example/jaas.conf" # cd kafka_example/ # tail -f simulated.log 2> /dev/null | kafka-console-producer --broker-list <your_kafka_broker>:9092 --topic logsTopic --producer.config client.properties |
More information about these settings can be found here.
2. NiFi pipeline
We will start off with the same NiFi pipeline we built in our previous article. If you recall, this flow was able to:
- Listen to the Kafka topic and consume its records
- Infer the CSV schema and convert it to an Avro one
- Write the record to a pre-existing Hive table
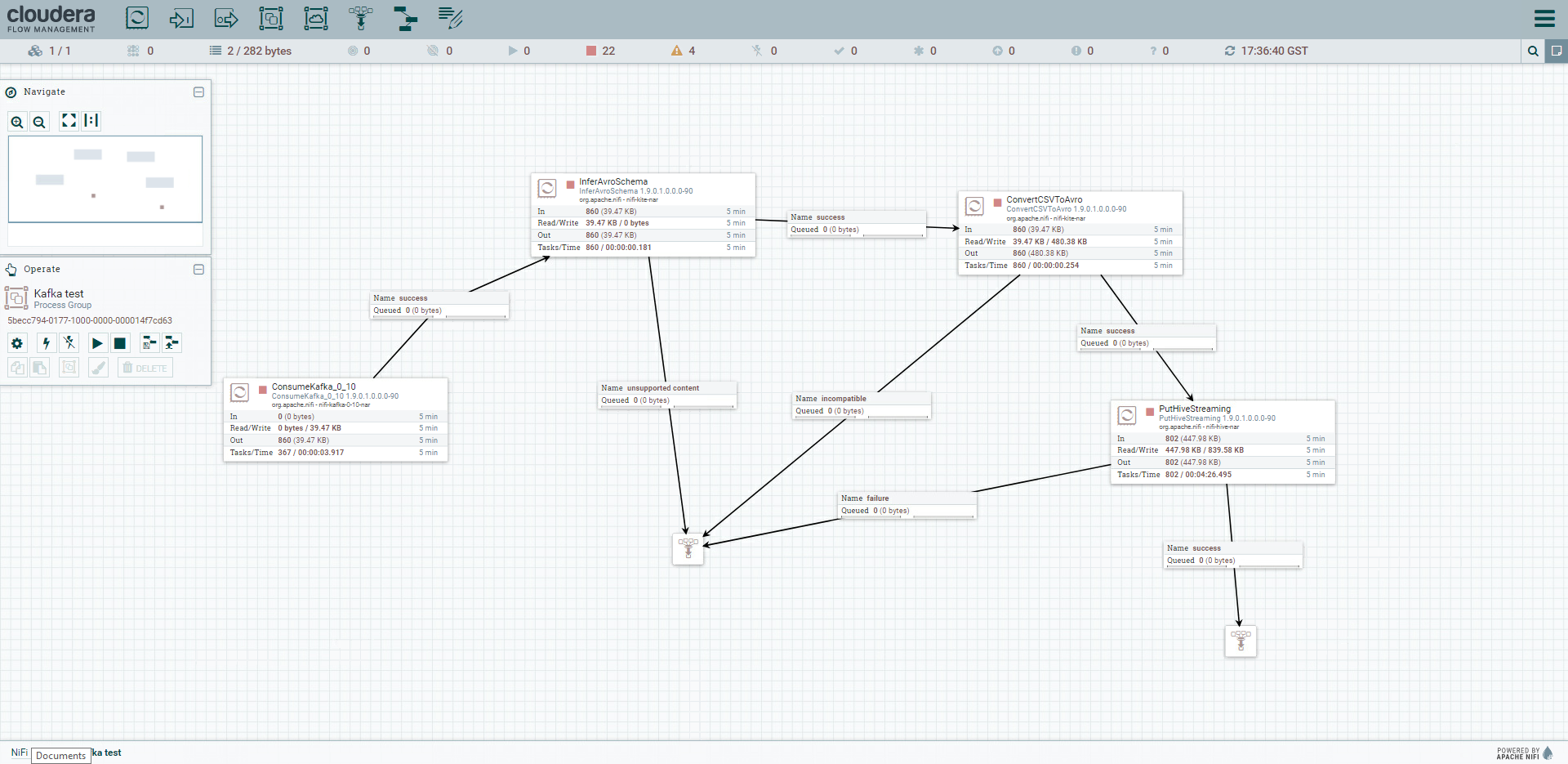
Figure 1: Complete view of the NiFi pipeline
In order to fulfil Kerberos requirements, we are going to modify the first and last processors: ConsumerKafka and PutHiveStreaming.
2.1. ConsumerKafka
This processor is required to listen to the Kafka topic in which our producer is sending log messages. It asks for the broker and the topic name. You also need to set a group ID, even though it is not relevant for our specific case.
In order to run our flow in a kerberized environment, we need to change a few properties related to the Security Protocol and the Kerberos credentials:
- Security Protocol: SASL_PLAINTEXT
- Kerberos Service Name: kafka, unless you named the Kafka service account differently.
- Kerberos Credential Service: A new one which we create for this purpose, specifying the Kerberos keytab location in the NiFi node(s) and the principal name as which we want to run the producer.
Notice how we are specifying the same information that we had to pass to the kafka-console-producer in the previous section, in the client.properties and jaas.conf files. NiFi essentially needs to somehow know the same when starting this processor, hence the need to set these parameters.
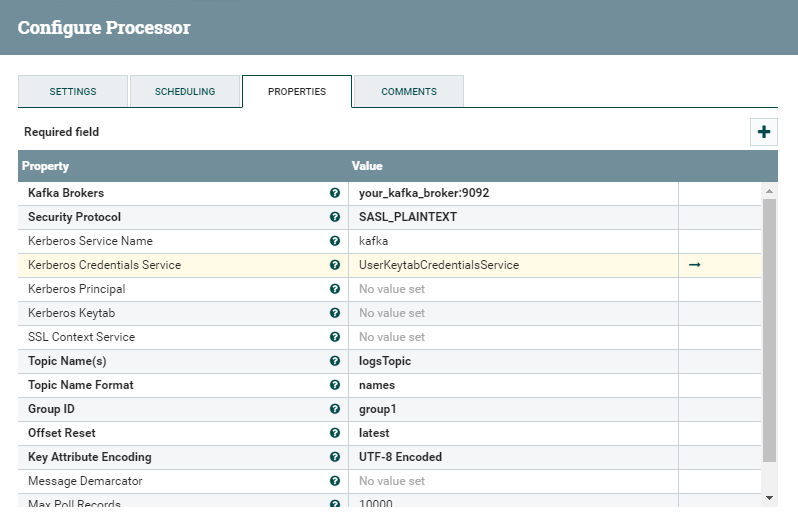
Figure 2: Details of the ConsumerKafka processor with Kerberos settings
The Kerberos Credentials include the Keytab and the Principal details. In our case, we run it with the credentials listed below (they do not necessarily have to be the same as the ones running the producer). Of course, you should adapt these values to the identity you decide to use.
- Kerberos Principal: valerio.dimatteo@CLEARPEAKS.COM
- Kerberos Keytab: /opt/cloudera/security/keytabs/valeriodimatteo.keytab
Note that nifi should have read and execute permissions over the keytab file, and that the Keytab location should correspond to an existing path in the NiFi node you are using. Furthermore (obviously) this user should have access to the Kafka topic.
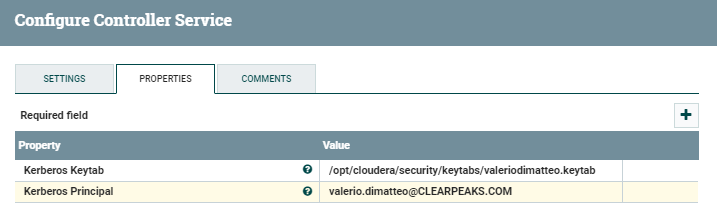
Figure 3: Details of the Kerberos Credential Service
2.2. PutHiveStreaming
Similarly to what we did for the ConsumerKafka processor, we need to update the PutHiveStreaming one with the details required by Kerberos. In this case, we only need to specify the Kerberos Credentials Service or (as we did, just to try the alternative way) specify the Principal and Keytab explicitly.
- Kerberos Principal: valerio.dimatteo@CLEARPEAKS.COM
- Kerberos Keytab: /opt/cloudera/security/keytabs/valeriodimatteo.keytab
Just like for the other processor, nifi should have access to this keytab and the user should have write access to the Hive table that is being written.
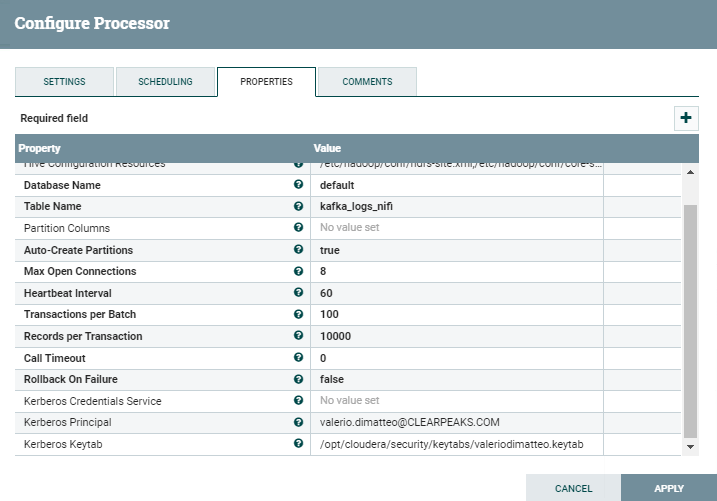
Figure 4: Details of the PutHiveStreaming processor with Kerberos settings
Conclusion – Integrating Nifi with Kerberos
As you can see, integrating NiFi with Kerberos is really not so complicated after all. All we need is to have an accessible keytab stored in the nifi node.
Once these settings are applied, we can start the NiFi flow and observe how the messages move through the queues (note the metrics across the whole pipeline and the counter in the Success sink of the PutHiveStreaming processor in the picture below).
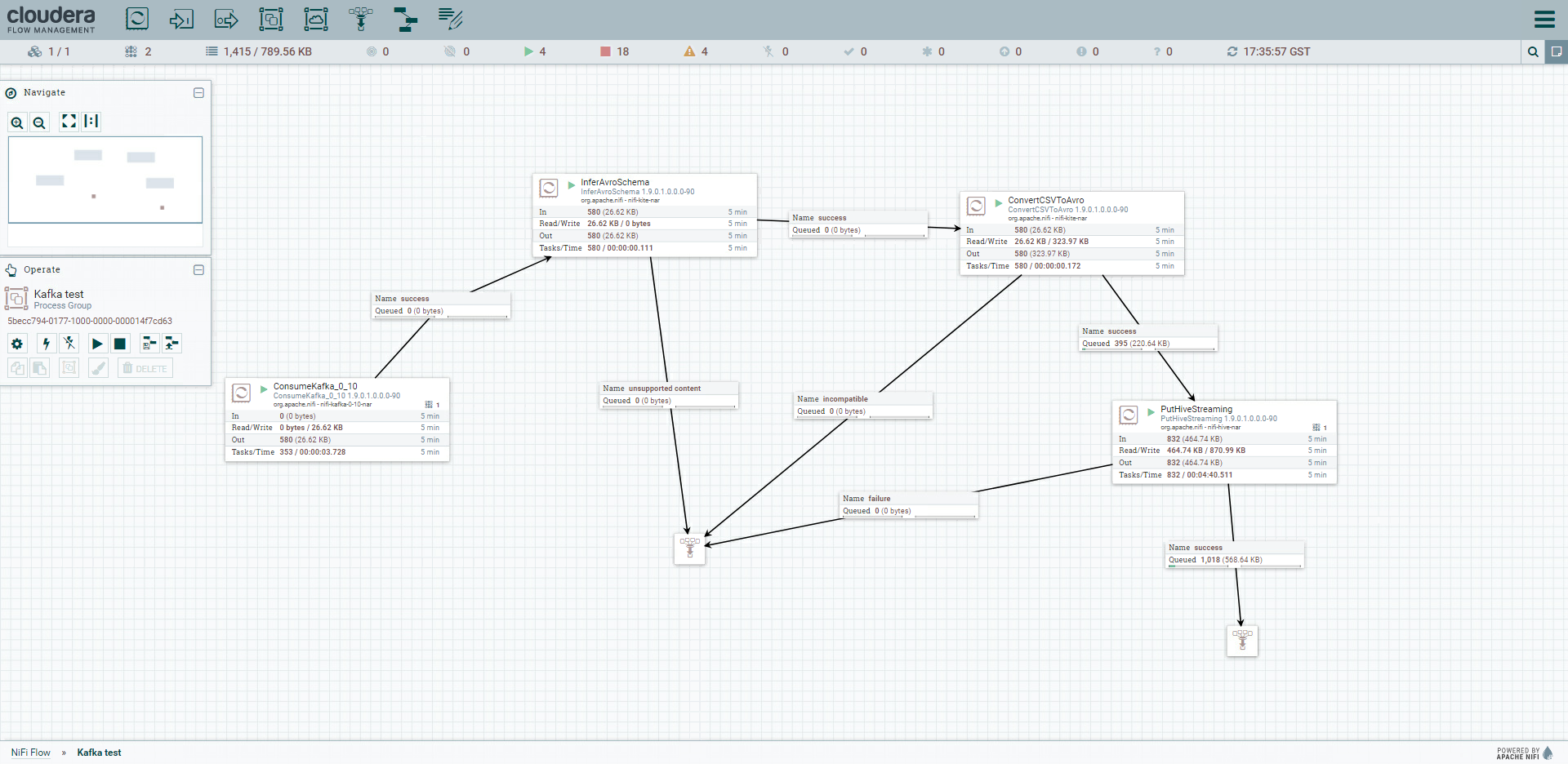
Figure 5: Details of the complete NiFi flow while running
Choosing the Right Keytab
In this demonstration, we used headless keytabs, i.e., the keytabs holding the credentials of a user principal. A headless keytab is the same across the whole cluster and does not contain any details about the specific hostname. Using a service keytab is not recommended for security reasons, but should you require to use it, perhaps for a NiFi demo, a nice trick would be to write the Principal in the following way (for example): nifi/${hostname(true)}@CLEARPEAKS.COM.
The ${hostname(true)} bit will be replaced by whatever host NiFi will be running on, therefore allowing you to run the same flow on different nodes without worrying too much about the Principal details (provided that the host specific service principal is valid).
Next steps
NiFi and Kafka form a really powerful combination which is gaining more and more traction thanks to Cloudera Data Flow, Cloudera’s complete offering for streaming solutions. As you saw in this article, however, integrating it with Kerberos requires a tiny bit of care. Luckily, we are here to help you!
In our next articles, we will have a look at how we can integrate this setup with other popular tools such as Dataiku (to run AI/ML predictions on streaming data), and PowerBI (to display streaming data in real-time). To get regular updates on our blog posts and other CoolThings, sign up for our newsletter.
If you have any questions or doubts, or are simply interested to discover more about Cloudera and its Data Platform in general, simply contact us. Our certified experts will be more than happy to help and guide you in your journey towards the ultimate Enterprise Data Platform!

The post Streaming Data to Hive Using NiFi and Kafka in a Kerberized CDH Cluster appeared first on ClearPeaks.