Generation of real-time data is increasing exponentially year on year, with data stream types from weather reports and sensors to stock quotes and tweets, data that is constantly changing and updating. Businesses can process this data at the time it is generated to get insights and make real-time decisions. For example, a sensor giving a temperature measure above a certain threshold could delay or abort a rocket launch, technology that could have prevented the Space Shuttle Challenger disaster. At ClearPeaks we have faced several real-time data use cases with a range of different business requirements, and in this article we will give you some hints at how to deal with real-time data by introducing a real case scenario. We will drive you through each of the steps taken in order to achieve our final solution.
Because of confidentiality we are not going to show our client’s data. Instead, we will use data generated by New York Citi Bike, the bike-sharing system in New York, and we will adapt the use case to something Citi Bike could face. We have used the Citi Bike dataset in the past in our ‘Big Data made easy’ series, where we went through a variety of big data technologies:
- Working with Talend Open Studio for Big Data and Zoomdata to create interactive dashboards with a Cloudera cluster.
- Working with StreamSets to ingest and transform real-time data with a Cloudera cluster.
- Working with Arcadia Data to create interactive dashboards natively with a Cloudera cluster.
- Working with Datameer to ease end-to-end operations in a Cloudera cluster.
You can also check out the solution for batch processing we implemented in the same project in our previous blog article: Big Data Analytics in Amazon Web Services.
At ClearPeaks, we provide analytics consulting for a wide range of client profiles, getting exposure to data architectures of companies who are just starting out with analytics all the way up to some of the most advanced data organizations in the world. Over the past months we have been seeing more and more companies starting their path in the cloud and many of them do so in Amazon Web Services. This article summarizes ClearPeaks’ experience while implementing a real-time architecture in Amazon Web Services.
1. Business requirements
Our client required a solution to manage the data being generated by their bike system in real time. This data was generated every 10 seconds and contained the status information of every bike station in the city. The company was quite new and had to put an architecture into place that could scale as business grew without increasing administration overheads – for this reason we decided to use AWS services. To improve customer experience, the company aimed to identify peak hours, to prevent empty or full stations, to spot the most popular stations, to reduce breakdown frequency, etc. It also had to account for flexibility: they wanted to add electric bikes, which would mean new fields generated at the data source. There is no other way to tackle these challenges other than data analysis, which leads us to build a storage layer and feed it with prepared data for business analysts. Business analysts are responsible for extracting business insights from curated data.
2. Functional analysis and development
From the business requirements we can conclude that our final solution should provide:
- Real-time data ingestion
- Scalability
- Minimal administration
- Flexibility to adapt to business changes
- Storage layer
- Real-time data processing
- Developed mostly on AWS stack
Considering all the points above we designed and implemented a nice, simple architecture.
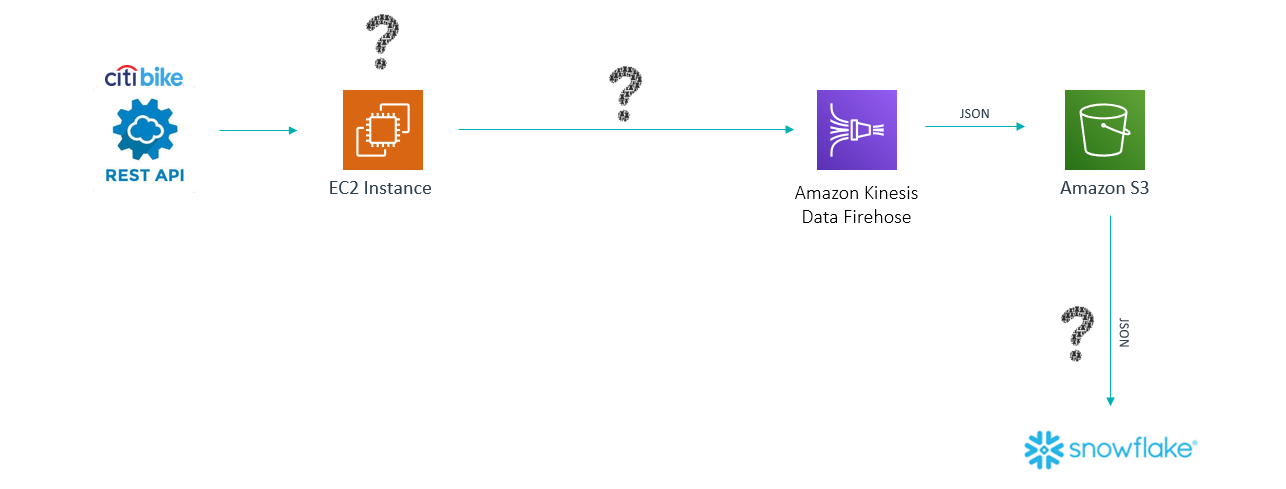
Figure 1: First architecture solution
This is the first attempt at achieving a robust solution. It covers some of the requirements whilst failing to meet some of the others, but it gives us a starting point to work on to reach the final architecture. The question marks in the picture represent issues we have to face with the current solution. First, let’s review each of the components and explain why we included them.
Citi Bike Rest API: Citi Bike provides an endpoint to extract the data of all the stations’ statuses. This data is updated every 10 seconds and a call to this URL returns it in a JSON format. Despite defining this source as real time, technically it is considered near-real time, as it is updated every 10 seconds. Real-time sources send updates every second or less.
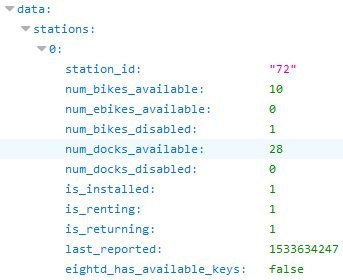
Figure 2: Sample data from the data source
EC2 Instance: There is Python script running on an EC2 instance that extracts the data from the Citi Bike endpoint every 10 seconds. Using the boto3 SDK, this script sends the data to Amazon Kinesis Data Firehose (we’ll explain that service below). Yes, the script does the job perfectly, but what if we switch it off? What if any of our team needs to modify the code? Should we administer a server for such a small task? We need to replace it with an AWS PaaS that can answer these questions.
Amazon Kinesis Data Firehose: The Kinesis service in AWS is one of the flagships of the AWS stack. It permits you to collect, process and analyze real-time streaming data such as video, audio, application logs, website clickstreams and IoT telemetry data for machine learning, analytics, and other applications. The Kinesis service has four components: Kinesis Data Streams, Kinesis Data Firehose, Kinesis Data Analytics and Kinesis Video streams. We used Kinesis Data Firehose because it allows the ingestion of real-time data and pushes it to a destination. There are 4 possible destinations: Amazon S3, Amazon Redshift, Amazon Elastic Search and Splunk. However, it is not possible to apply real-time processing before sending the data to a destination. Moreover, Kinesis Data Firehose is not a storage layer and it is not possible to consume data directly from it.
Amazon S3: Amazon S3 is a simple storage service that offers an extremely durable, highly available, and infinitely scalable data storage infrastructure at very low cost. Any data lake in AWS is built on S3. In our case, S3 will store the data coming from the Kinesis Firehose. It will create a historic data store and will be updated every time Firehose sends data in. S3 can store any kind of file format – we will keep the JSON format for flexibility reasons.
Snowflake: An SaaS data warehouse hosted on AWS, Azure or Google. It easily scales up or down the computing power of the data warehouse depending on user requirements. Data is stored at scale in native formats (structured and semi-structured). It is a Gartner leader in data management solutions for analytics.
To overcome the issue of having an IaaS-based component in the picture, we replaced it with an AWS Lamba.
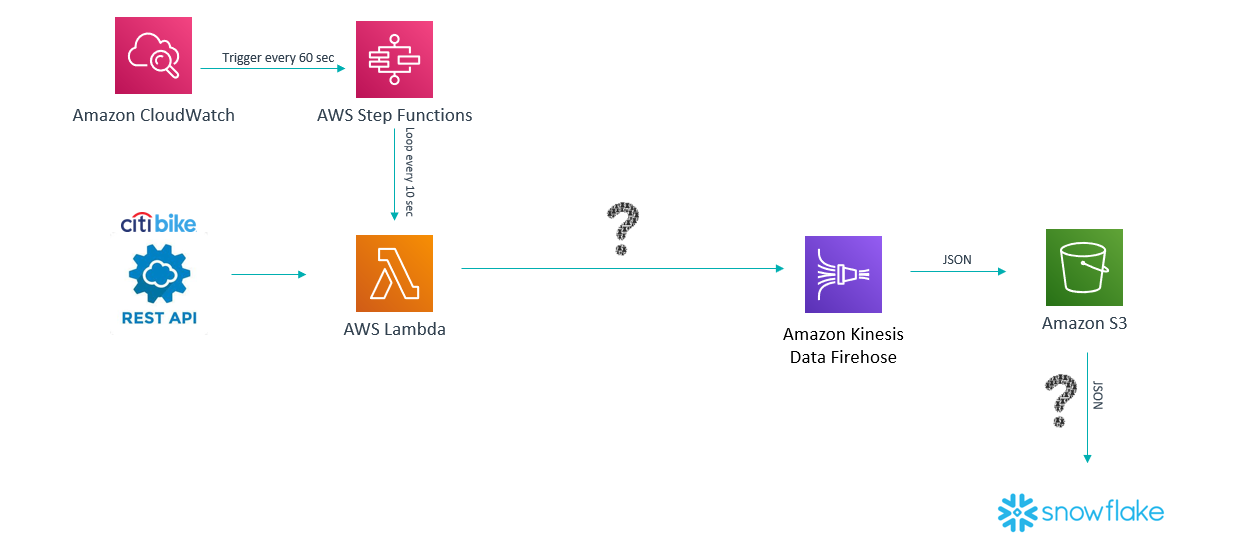
Figure 3: Second architecture solution
AWS Lambda: Function as a service. It can run code without provisioning or managing servers. It is executed on demand and supports languages like Node.js, Python, Java, C#, Go, PowerShell and Ruby. In our use case, it is preferred over a virtual machine EC2 in AWS. Most compute resources of the EC2 instance would be idle most of the time but we would have to pay for them anyway. Lambda’s cost per execution is very low and will significantly reduce costs.
AWS CloudWatch: A monitoring and observability service to track all AWS services with logs, metrics and events: applications, performance, optimize resource utilization, unified view of operational health. It can trigger the execution of other AWS services. Lambda needs a trigger to be executed, so combination with AWS CloudWatch is key to our solution. However, there is a limitation on the trigger scheduling: AWS CloudWatch cannot trigger events with a frequency of less than a minute. We need Lambda to be executed every 10 seconds to cover every update of the source system, so a new service comes into play: AWS Step Functions.
AWS Step Functions: A fully-managed service that coordinates the component applications and microservices using visual workflows. Its main applications are to consolidate data from multiple databases into unified reports, to refine and reduce large data sets into useful formats, or to coordinate multi-step analytics and machine learning workflows. AWS Step Functions can perform work, make choices, pass parameters, initiate parallel executions, manage timeouts, or terminate your workflow with a success or failure. In our scenario, we will use AWS Step Functions to execute Lambda every 10 seconds.
Now that we have covered ingestion, we should focus on the real-time data processing.
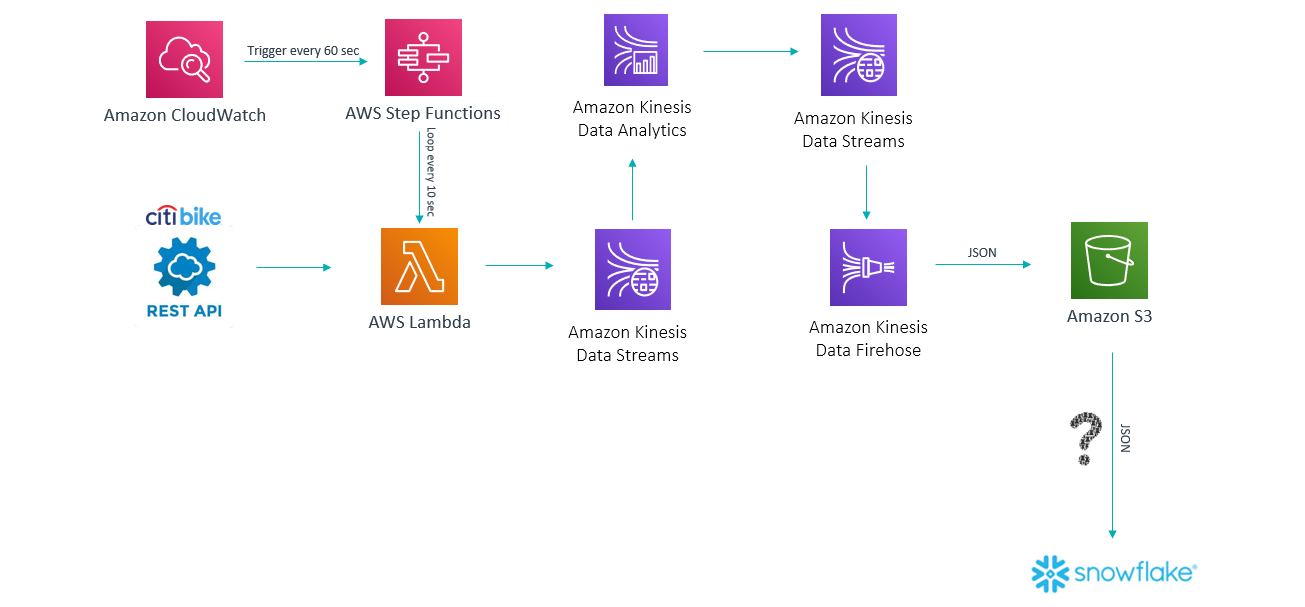
Figure 4: Third architecture solution
Instead of pushing data directly into AWS Kinesis Firehose, we’ll send it to Amazon Kinesis Data Streams.
AWS Kinesis Data Streams: A massively scalable and durable real-time data streaming service, analog to the open-source Apache Kafka. It acts as a Kafka topic where we can produce or consume data, offering a retention period ranging from 24 to 168 hours. Data in an AWS Kinesis Data Stream can be exposed to real-time visualization tools or can be processed using AWS Kinesis Data Analytics.
AWS Kinesis Data Analytics: This AWS service lets you analyze streaming data in real time using SQL queries. It can connect to a Kinesis Data Stream source and push data to another Kinesis Data Stream or Kinesis Data Firehose.
Let’s look at some simple transformations we performed on the data.
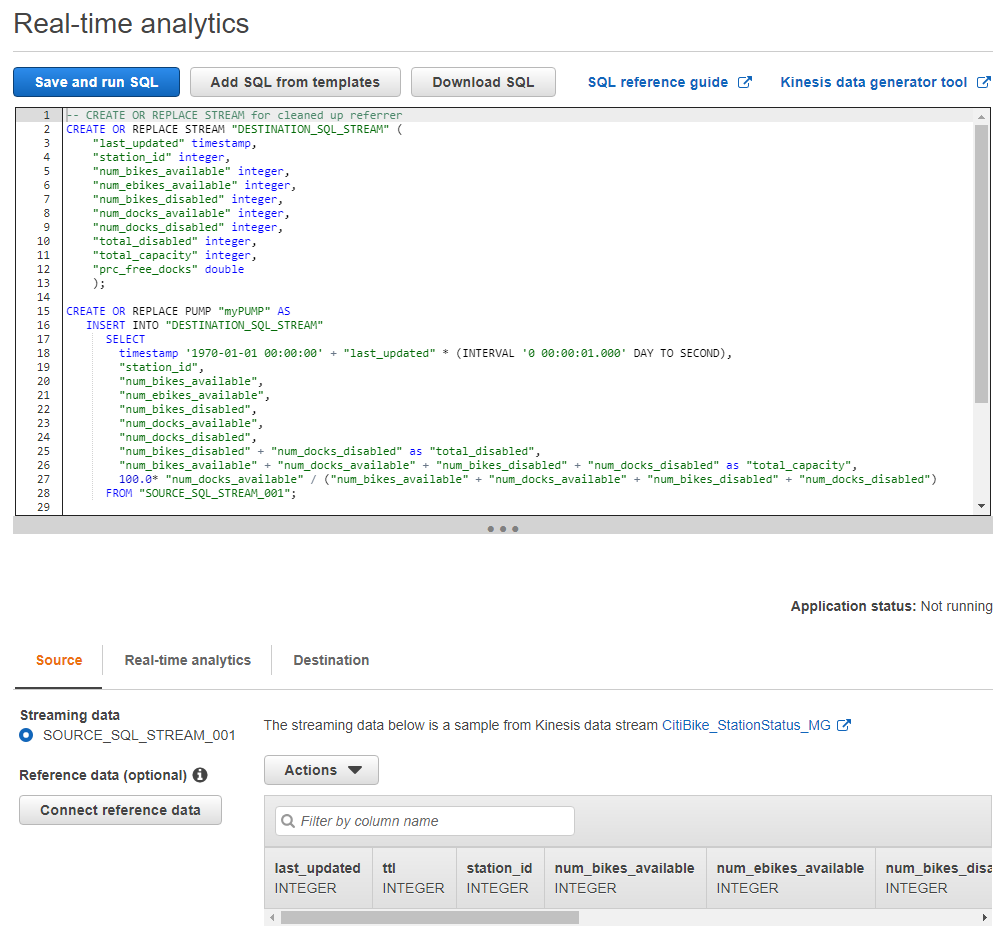
Figure 5: Real-time transformations in AWS Data Analytics
We can use SQL code to make our transformations: notice that we transformed an integer number into a date type and summed several columns to create a new one. The output of this query will be pushed to another Kinesis Data Stream before being ingested into Kinesis Data Firehose. That’s a best practice if we need to expose this real-time processed data to any other service.
At this point, our architecture is almost finished. Our data is being extracted from the Citi Bike API by an AWS Lambda every 10 seconds, pushed to a Kinesis Data Stream, processed by Kinesis Data Analytics and sent to a new Kinesis Data Stream; then Kinesis Data Firehose pushes data to AWS S3 from the Kinesis Data Stream. Now we get to the final step: sending the data to Snowflake.
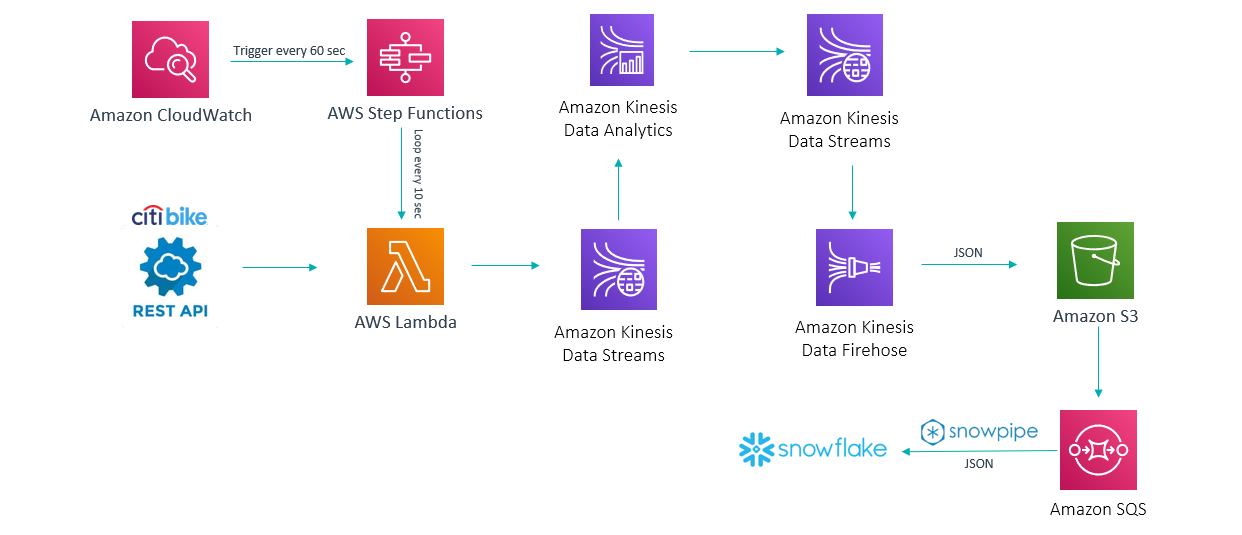
Figure 6: Final Solution
AWS SQS: A fully-managed message queuing service. It sends, stores, and receives messages between software components in any volume. It is great for decoupling and scaling microservices, distributed systems, and serverless applications. This service receives a message every time a new file is created in the S3 bucket and triggers the Snowpipe process.
Snowpipe: Snowflake’s continuous data ingestion service. You can define a pipeline to load fresh data in micro-batches as soon as it’s available.
Data arrives in JSON format. Snowflake allows you to store semi-structured data and permits analytics on top of it with easy SQL: this satisfies the flexibility requirement. The solution will handle data structure changes: if a new attribute is added in the data source, our pipeline will not break. We will just have to adapt our SQL final queries or visualization tool to account for the new metric or dimension. The same applies for removed attributes: our queries will output nulls or 0s when querying data from that point in time onwards, but will never give us an error.
Conclusion
In this article we have covered the process of defining an architecture, step by step and in a real business case. Our solution meets all the requirements we faced at the beginning of the project:
- Real-time data ingestion: achieved with AWS Lambda, CloudWatch, AWS Step Functions and the Kinesis components.
- Scalability: intrinsic to cloud services.
- Minimal administration: achieved by using PaaS services.
- Flexibility to adapt to business changes: achieved by keeping semi-structured data from source to destination in JSON format.
- Storage layer: achieved with S3 and Snowflake.
- Real-time data processing: achieved with the Kinesis components.
- Developed mostly on AWS stack: Yes.
We hope this can help you to define your enterprise architecture. In ClearPeaks we have a team of big data consultants that have implemented many use cases for different industries using these services. If you are wondering how to start leveraging real-time technologies to improve your business, contact us and we will help you on big data journey! Stay tuned for future posts!
The post Real-Time Analytics with AWS appeared first on ClearPeaks.