With the acquisition of Hortonworks in October 2018, Cloudera made a very clear and loud statement: they wanted to become the undisputed biggest players in the Big Data industry.
They already offered one of the best Big Data platforms on the market (CDH), but now, they are taking one step forward: their newest product, Cloudera Data Platform (CDP), aims at becoming the ultimate data solution for all data-driven enterprises.
At ClearPeaks, we are proud partners of Cloudera, and our team of Cloudera certified consultants is always up to date with the newest solutions, in order to always be one step ahead and be able to deliver the best answer to every scenario.
CDP was only released on September 24th, but we were lucky to get an early look at it when we attended the Cloudera Roadshow in Dubai just a few weeks ago; in this article, we will present it, describing how it relates to CDH, what the first release is looking like, and what services it will include once entirely released.
1. The Enterprise Data Cloud
To prove their ambitions, Cloudera coined a new term for what they believe is the present and future Big Data industry, the Enterprise Data Cloud, and identified themselves as the first Enterprise Data Cloud Company.
But what is the EDC? To put it in their words, it is the solution for all the data-related problems of the modern enterprises:
- data isolation and lack of tool interoperability
- data being spread across multiple sources
- enterprise/government security policies that often limit productivity
An Enterprise Data Cloud is the answer to all of this: a multi-cloud, elastic, multi-function, secure and open data solution.
2. Cloudera Data Platform
This is where CDP comes in.
Labelled as the first Enterprise Data Cloud solution, Cloudera Data Platform is the result of the combination of the best CDH and HDP (Hortonworks Data Platform) services, into one big, comprehensive PaaS offering for all things data.
But it is much more than that. Additionally, it introduces some Analytics Services, pre-defined cloud-based solutions that are tailored to tackle the most common and important analytics workloads: Data Warehouse, Machine Learning, Data Engineering, Data flow & Streaming and Operational Database (but only the first 2 are currently available).
CDP can manage data in any environment, including public clouds like AWS, Azure and GCP (Google Cloud Platform), and it is able to intelligently auto-scale workloads and infrastructure up and down to maximize efficiency and minimize costs.
It is intended to be the ultimate, end-to-end (or Edge2AI, as they call it) solution to any analytics case, offering a single pane of glass view over all the enterprise data and diverse workloads.
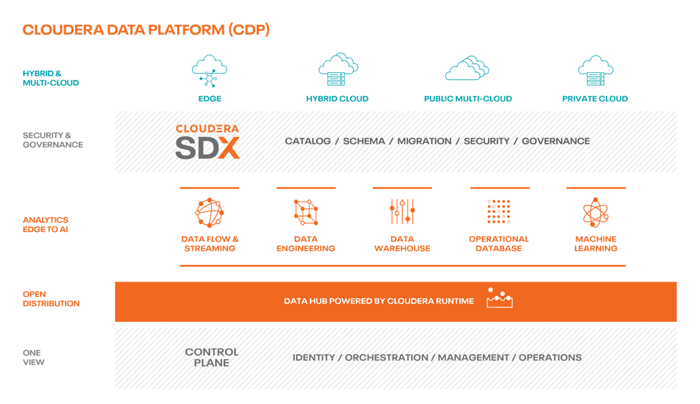
Figure 1: CDP overview. Source: https://blog.cloudera.com/cloudera-data-hub-where-agility-meets-control/
As you can see, the number of components is quite large; many of them are new, others have been rebranded, and some, as mentioned, will be released in the future.
The whole ecosystem is complex to simplify in a single picture, but here are the main elements that make up the Cloudera Data Platform today:
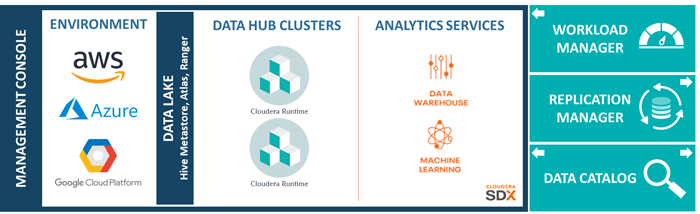
Figure 2: Logical architecture of CDP components
- Environment:
the AWS/Azure/GCP provided elastic cluster in the cloud. CPD offers a single pane of glass over all of them, so companies are able to monitor, manage and use multiple environments , by multiple providers, in multiple regions of the world.
- Data Lake:
a special cluster with no computing power, tied to an environment, that provides a shared data lake to all the services and workload clusters running in it. It includes a Hive Metastore to share tables metadata across all the lake, Atlas as a powerful data catalog and lineage repository, and Ranger for horizontal security and authorization across all the environment.
- Data Hub:
the evolution of CDH/HDP into a cloud-based, elastic cluster, deployable with a wizard-like interface with just a few clicks. It is powered by the new Cloudera distribution, called Cloudera Runtime (basically, CDH 7 merged with the best of HDP). You can have multiple Data Hub clusters in each environment, all connected to the same Data Lake but with different services and infrastructure.
- Data Warehouse:
first Analytics Service. It is a special auto-scaling cluster, specifically tailored for self-service independent DWHs. It also runs on the same data lake, in a specific environment, but it is not managed by YARN. It is made of Database Catalogs and computing resources called Virtual Warehouses.
- Machine Learning:
second Analytics Service. It is CDP’s own cloud native version of the Cloudera Data Science Workbench. It offers a container-based unified self-service machine learning platform, with the most popular IDEs like Jupiter and Zeppelin and the most popular languages and libraries (Spark, Python, Tensorflow, Scala, R, etc.). Like the other services, it runs on the same shared data lake, but it is powered by Kubernetes.
- SDX:
Cloudera Shared Data Experience. Thanks to Ranger and Atlas, it offers a single control panel over the whole environment, with shared metadata, data catalog and lineage, security and governance.
- Data Catalog:
cross-environment service that offers a data asset repository over all the enterprise data lakes, to organize, understand, govern and curate data globally.
In the following sections, we will delvee into the details of the Data Hub and of the 2 Analytics Services that are available today: Data Warehouse and Machine Learning.
3. Data Hub
Data Hub is a core service of the new CDP, and most probably the one that legacy CDH and HDP users will be most familiar with.
Essentially, it is the new, evolved version of the CDH and HDP distributions: it allows users to deploy an entire cluster on the cloud, in just a few clicks, choosing amongst a set of pre-defined templates (specific to a certain workload type) or by defining a customized set of services and nodes.
The clusters ship with the new Cloudera distribution, called Cloudera Runtime. It is the result of the combination of Cloudera’s and Hortonworks’s best features; for example, Ranger instead of Sentry, Cloudera Manager instead of Ambari, and so on.
From the Management Console, users are currently able to choose one of the following pre-defined templates:
- Data Engineering
HDFS, Hive, Hue, Livy, Oozie, Spark, Yarn, Zeppelin, ZooKeeper - Data Mart
HDFS, Hue, Impala
Data Hub clusters have automated HA configuration of all critical services and are able to use auto-repair to replace failed instances; moreover, they are easily resizable to scale up/down and their instances are ephemeral, to optimize the costs.
Most importantly, current CDH and HDP customers will be able to easily migrate to this new version without disruption.
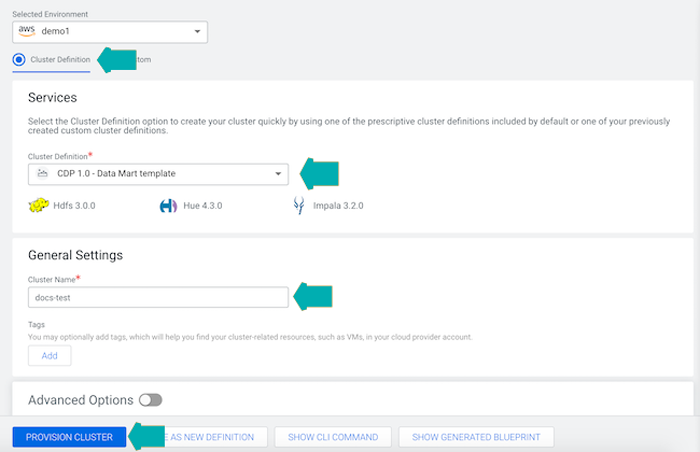
Figure 3: Data Hub service creation GUI. Source: https://docs.cloudera.com/data-hub/cloud/create-cluster-aws/topics/mc-create-cluster-from-template.html
4. Data Warehouse
Data Warehouse is the first of the new Analytics Services included in CDP.
It isan auto-configured, fully isolated, auto-scalable, ephemeral, fault-tolerant and security-compliant Data Warehouse in the cloud.
Isolated means that each DWH will run its workloads in a different, optimized cluster, effectively eliminating the problem of having noisy neighbours and ensuring that every user will only access the right portion of data.
All the DBA needs to do is select the size range and the concurrency, within which the cluster can automatically scale up or down depending on the need.
Once deployed, the DWH can be queried via HUE or DAS (Data Analytics Studio).
The main components of the CDP DWH are:
- Database Catalog:
the metadata collection associated to a DWH context. It contains tables and view definitions as well as the security and governance criteria set in CDP that apply to this context. It can be attached to multiple DWHs.
- Virtual Warehouse
the instance of compute resources associated to a DWH. It is linked to a catalogue, so it provides access to the data in tables and views in the data lake that are included in a specific catalogue, and can run either on top of Hive or on top of Impala. It is auto-scalable and auto-suspending, with configurable criteria.
Of course, Cloudera Data Platform offers the possibility to use third-party tools, like BI reporting tools, with the DWH service. To do so, for every Virtual Warehouse, it provides the DWH URL and the JDBC driver.
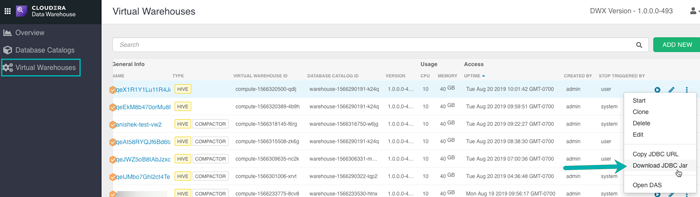
Figure 4: Virtual Warehouse instances in a CDP environment. Source: https://docs.cloudera.com/data-warehouse/cloud/managing-warehouses/topics/dw-integrating-third-party-tools.html
5. Machine Learning
Machine Learning is the second Analytics Service included in the first release of CDP. It is a cloud-based, self-service machine learning platform, that enables users to deploy secure, auto-scalable and efficient ML and AI workloads.
CML is built on ML Workspaces, which are ephemeral clusters run on Kubernetes and support containerized execution of Python, R, Scala and Spark; it also supports popular IDEs like Jupiter, Zeppelin or PyCharm.
It is the natural evolution of CDSW. However, unlike its predecessor:
- it doesn’t need a dedicated CDH/HDP cluster
- it doesn’t run on the gateway node
- it doesn’t use YARN
- it can access any data stored in CDP
Of course, CML can easily be usd to train and deploy models, that once deployed, are stored as an immutable docker image.
A REST API is provided to be easily plugged in other applications. CML even creates code snippet to easily copy-paste the API calls into your R o Python code.
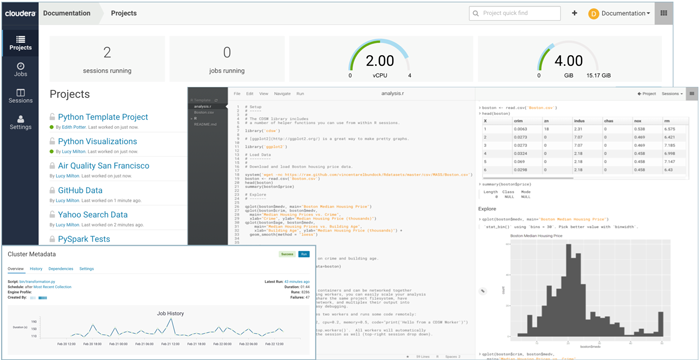
Figure 5: The CDP ML app. Source: https://docs.cloudera.com/machine-learning/cloud/product/topics/ml-product-overview.html
What’s next
As mentioned, not all the Analytics Services are immediately available from the first release. Besides Data Hub, Data Warehouse and Machine Learning, the current plan is for the following elements to be added to the stack:
- Data Flow & Streaming (probably an evolution of CDF)
- Data Engineering
- Operational Database
Furthermore, the first release is exclusively for AWS Public Cloud, but Azure and GCP compatibility as well as the Private Cloud versions are already scheduled to be released soon. The On-Premises version, called CDP Data Center, will be generally available later this year, with annual subscriptions starting at $10,000 per node. Check the detailed pricings here for additional information.
While the Private Cloud will most probably resemble the current CDP in its entirety, the CDP Data Center will be more similar to the classic CDH and HDP, with the updated Cloudera Runtime distribution and no cloud-related extra service (like the Management Console). We will find out soon.
The post Introduction to Cloudera Data Platform appeared first on ClearPeaks.