Something is changing in the Business Intelligence (BI) scene. BI is evolving, driven by Big Data, Cloud and Advanced Analytics. The combination of these technologies and methods has unveiled the possibility of tackling new use cases that could not even have been considered before.
Every company is a case in itself, so we’re not going to say that if you don’t stay ahead in BI then you’ll get left behind. There are cases in which a traditional BI setup may well be sufficient for many years to come. Nevertheless, it is true that pretty much every organization out there is, at the very least, considering this evolution, so you should be doing so too…
Let’s start with the basics. Generally speaking, a traditional BI architecture comprises of:
- an Extract-Transform-Load (ETL) or an Extract-Load-Transform (ELT) tool that periodically integrates data from structured data sources – databases or CSV/Excel files – and transforms and reorganizes the data into
- a BI data model made of dimension and fact tables, suited to efficient reporting
- a Data Warehouse (DWH) that is, essentially, a relational database (RDBMS) that stores the data transformed by the ETL/ELT tool into the BI data model
- and a reporting tool that leverages the data in the Data Warehouse by using the underlying SQL engine to create dynamic visualizations that are organized into reports and dashboards for business users.
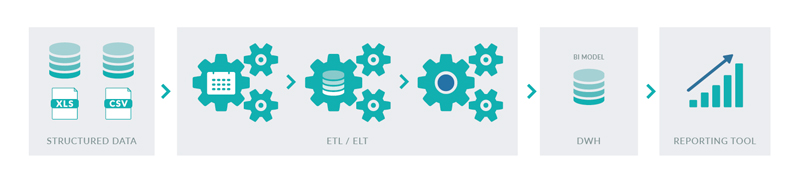
Figure 1: Traditional BI architecture.
This traditional BI architecture, as depicted in Figure 1, has been used for decades now and is still the most dominant architecture for business analytics. However, as mentioned in the introduction, the BI scene is evolving, driven by Big Data, Cloud and Advanced Analytics, so let’s analyze how each of these is helping to evolve BI.
In this, the first article in a series about Big Data, Cloud and Advanced Analytics, we´ll deep-dive into Big Data and the next generation of Business Intelligence…
Big Data, as its name suggests, is all about data. Quoting Wikipedia, “Big data is a term for data sets that are so large or complex that traditional data processing application software is inadequate to deal with them.” The Wikipedia entry also mentions the challenges facing Big Data as well as its Vs, the most important ones being Volume, Variety and Velocity. It also refers to the other Vs that have been added – Veracity and Value. Even more Vs can be added, up to 42 according to a blog article by Tom Shafer that builds on the sometimes excessive Big Data hype.
Big Data is all about data, but it is also about a set of technologies that have been created, or old technologies that have evolved, to allow dealing with Big Data. These technologies rely on computer clusters that leverage distributed storage and distributed computing. There are many technologies available – you can check, for example, the famous Matt Turck Big Data landscape. The most used set of technologies is by far Hadoop and its ecosystem; however, it is not the only Big Data technology out there. In BI it´s also relevant to talk about how traditional DBs have evolved to tackle Big Data.
The Hadoop ecosystem
There are many terms related to the Hadoop ecosystem (from now on Hadoop) such as Data Lake, Data Factory, Data Reservoir, Big Data Warehouse, etc., and some of these terms are more popular than others. It once seemed like Hadoop and related terms were competitors of traditional BI architecture, but the current trend is to see and treat them as complementary.
But what can Hadoop, in any or all of its faces and terms, do for BI? Hadoop is a system – a computer cluster – that allows dealing with:
- Any amount of data (Volume), if enough horse-power is allocated to the task. Hadoop is not magic; if you have a lot of data you are going to need a lot of computers to deal with it – Hadoop just makes it easier. Of course, Cloud is the perfect partner for Big Data since it gives immediate access to (almost) infinite compute resources and allows straightforward scaling up and down systems. We will talk more about Cloud in a later blog article.
- Any type of data (Variety), structured data like databases and CSV/Excel files, but also unstructured or semi-structured data such as web and click logs, social media, sensor data, etc..
- Any time constraints regarding ingestion, processing and analysis (Velocity). Data can be inserted in batch mode with some periodicity (usually daily) as in traditional BI, but also in real time, i.e. when generated. Likewise, data can be processed and ready for analytic consumption in real time.
For BI, the above-mentioned points mean that we are no longer limited to structured data updated once a day, with a lot of data leading to poor performance. This opens up a world of possibilities: we can now use and analyze any type of data of any size and at whatever speed we need (if the necessary compute resources are allocated).
But how does Hadoop integrate into BI architecture? Let’s look at a few points:
- Even though Hadoop can actually be used to replace both ETL/ELT tools and DWH RDBMS technologies, the most common approach is still to use a RDBMS as a DWH and Hadoop as the engine that prepares the (Big) data for it. Some of the reasons for keeping a RDBMS as a DWH are that (i), in some cases, a considerable investment has already been made in the existing DWH, (ii) traditional RDBMS technologies are more robust security-wise, (iii) RDBMSs are more mature, (iv) the SQL language in RDMBSs offers more features and (v) RDBMSs are easier to use.
- As just mentioned above, Hadoop can replace the ETL/ELT tool. However, most popular ETL/ELT tools have evolved to be able to use the underlying processing engines in Hadoop clusters (Spark, MapReduce, etc.) for their ETL jobs which can be created with familiar user-friendly APIs thus hiding the complexity of Hadoop. This is sometimes called Extract-Hadoop-Load (EHL), and at other times it is referred to as Data Factory.
- A very common use of Hadoop is as a Data Lake, the repository where an organization stores all its data, both raw and processed. Hadoop also provides the (ecosystem) tools to aid in the processing and analysis of the data.
- In some cases, Hadoop is used as an offloading area for data that no longer has space in the DWH, or simply as an extension of the DWH. Thanks to SQL-on-Hadoop tools like Hive-LLAP or Impala, data can still be accessed with low latency by all reporting tools. In some cases, this is called a Data Reservoir.
- In other cases, Hadoop ecosystem tools (Flume, Spark Streaming, Kafka, etc.) are used to create real-time Big Data ingestion and processing pipelines that allow immediate data analysis.
- Hadoop can also be used as an enabler for Advanced Analytics use cases. Machine Learning processes can be very time-consuming when done over large data sets, and in many cases large data sets are needed. Hadoop offers engines (such as Spark ML) that allow running Machine Learning and Data Science methods on Big Data. We will be looking at Advanced Analytics in a later blog article.
Developments in database technologies
As mentioned earlier, Hadoop is not the only technology that is helping to evolve BI. Traditional BI architectures usually rely on single-server row-based RDBMSs as the technologies used by their DWH. These work well enough with small amounts of data (less than few TBs), but with larger data sets these technologies struggle. Luckily, some new developments have thrived in recent years and new database technologies have appeared while traditional RDBMSs have evolved to include:
- Columnar storage formats that offer much better performance for analytical queries (such as aggregations) than their row-based counterparts. For example, when computing the average age of a customer base, access to data is much more efficient if all the ages are stored together.
- Compressed formats that use advanced compression algorithms that leverage, among other optimizations, columnar formats to reduce IO operations.
- In-memory processing that leverages and optimizes the use of the memory to decrease the latency of queries using smart caching mechanisms.
- Massively Parallel Processing (MPP) engines that leverage multiple cores and multiple machines to offer great performance.
So, in next-generation BI architectures, in addition to Hadoop, it is also common to replace the underlying RDBMS technology of the DWH with a new (or enhanced) solution that leverages the above-mentioned optimizations. In some cases, where it is not possible to replace the DWH, an improved DB with the above-mentioned enhancements is used alongside the DWH and acts as an accelerator for BI queries (for example, by replacing Data Extracts used in some popular BI tools).
Next-generation Business Intelligence
If we integrated all the above-mentioned uses of Hadoop into a BI architecture and also upgraded our DWH DB technology to leverage all the above-mentioned optimizations, we would have the architecture depicted in Figure 2. This is, in fact, the template for the next-generation BI architecture that most organizations are targeting.
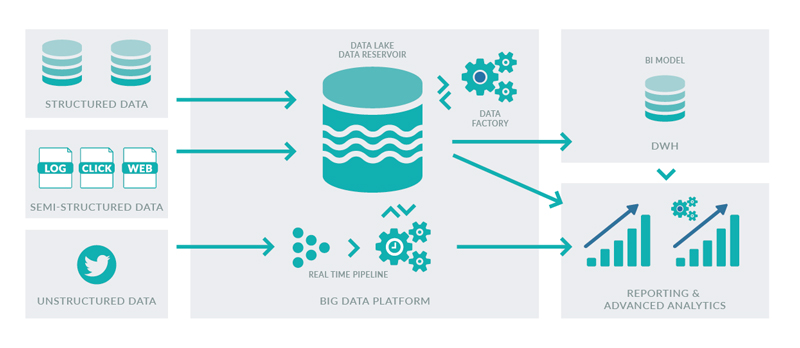
Figure 2: Next-generation BI architecture.
In this blog article we have been rather theoretical and we have not mentioned any specific technology vendor. In ClearPeaks, we have a team of experts to help you with your Big Data projects. We can:
- Analyze your BI architecture to determine if you need to upgrade to the next-generation BI.
- Help you define your Big Data strategy and identify Big Data use cases.
- Dive into the Big Data landscape and work together to find the most suitable technology matrix for your organization.
- Implement complex Big Data solutions including next-generation BI architectures tuned for your organization.
- Demonstrate the potential of Big Data in your organization through Big Data PoCs where we deploy your first Big Data environment and implement your first Big Data PoC use cases.
- Train your team with our Big Data training sessions.
For more information, please contact us and we will be happy to help you.
The post Big Data and next-generation Business Intelligence appeared first on ClearPeaks.